Распознавание текста | Яндекс.Облако — Документация
Создайте файл скрипта, например text_detection.go и скопируйте в него следующий код:
package main import ( "bytes" "encoding/base64" "encoding/json" "errors" "flag" "fmt" "io/ioutil" "log" "net/http" ) func GetIamToken(iamURL, oauthToken string) (string, error) { body, err := json.Marshal(&IamTokenRequest{YandexPassportOauthToken: oauthToken}) if err != nil { return "", err } resp, err := http.Post(iamURL, "application/json", bytes.NewReader(body)) if err != nil { return "", errors.New("Failed to obtain IAM token by oAuth token: " + err.Error()) } if resp.StatusCode != http.StatusOK { return "", fmt.Errorf("Auth service returned status %d", resp.StatusCode) } defer func() { err := resp.Body.Close() if err != nil { log.Fatal(err) } }() respBody, err := ioutil.ReadAll(resp.Body) if err != nil { return "", err } iamTokenResponse := &IamTokenResponse{} err = json.Unmarshal(respBody, iamTokenResponse) if err != nil { return "", err } return iamTokenResponse.IamToken, nil } type IamTokenRequest struct { YandexPassportOauthToken string `json:"yandexPassportOauthToken"` } type IamTokenResponse struct { IamToken string } func RequestAnalyze(visionURL, iamToken, folderID, imageBase64 string) (string, error) { request := BatchAnalyzeRequest{ FolderID: folderID, AnalyzeSpecs: []AnalyzeSpec{ { Content: imageBase64, Features: []Feature{ { Type: "TEXT_DETECTION", TextDetectionConfig: TextDetectionConfig{ LanguageCodes: []string{ "en", "ru", }, }, }, }, }, }, } body, err := json.Marshal(&request) if err != nil { return "", err } req, err := http.NewRequest("POST", visionURL, bytes.NewReader(body)) if err != nil { return "", errors.New("Failed to prepare request: " + err.Error()) } req.Header.Set("Content-Type", "application/json") req.Header.Set("Authorization", "Bearer "+iamToken) resp, err := http.DefaultClient.Do(req) if err != nil { return "", errors.New("Failed to process request: " + err.Error()) } if resp.StatusCode != http.StatusOK { return "", fmt.Errorf("Service returned status %d", resp.StatusCode) } defer func() { err := resp.Body.Close() if err != nil { log.Panic(err) } }() respBody, err := ioutil.ReadAll(resp.Body) if err != nil { return "", err } return string(respBody), nil } type BatchAnalyzeRequest struct { FolderID string `json:"folderId"` AnalyzeSpecs []AnalyzeSpec `json:"analyzeSpecs"` } type AnalyzeSpec struct { Content string `json:"content"` Features []Feature `json:"features"` } type Feature struct { Type string `json:"type"` TextDetectionConfig `json:"textDetectionConfig"` } type TextDetectionConfig struct { LanguageCodes []string `json:"languageCodes"` } func main() { iamURL := "https://iam.api.cloud.yandex.net/iam/v1/tokens" visionURL := "https://vision.api.cloud.yandex.net/vision/v1/batchAnalyze" oauthToken := flag.String("oauth-token", "", "oAuth token to obtain IAM token") folderID := flag.String("folder-id", "", "Folder ID") imagePath := flag.String("image-path", "", "Path to image to recognize") flag.Parse() iamToken, err := GetIamToken(iamURL, *oauthToken) if err != nil { log.Panic(err) } imageData, err := ioutil.ReadFile(*imagePath) if err != nil { log.Panic(err) } imageBase64 := base64.StdEncoding.EncodeToString(imageData) responseText, err := RequestAnalyze(visionURL, iamToken, *folderID, imageBase64) if err != nil { log.Panic(err) } fmt.Print(responseText) }
Выполните скрипт из командной строки. В аргументах передайте OAuth-токен, идентификатор каталога и путь к файлу изображения:
cloud.yandex.ru
Оптическое распознавание текста (OCR) | Яндекс.Облако
В этом разделе описано, как работает возможность
Процесс распознавания текста
Распознавание текста на изображении состоит из двух этапов:
- Определение языковой модели для распознавания текста.
- Поиск текста на изображении.
В результате распознавания сервис вернет JSON-объект с распознанным текстом, его расположением на странице и достоверностью распознавания.
Определение языковой модели
Для распознавания текста в сервисе используется модель, обученная на определенном наборе языков. Некоторые языки сильно отличаются друг от друга (например, арабский и китайский), поэтому для них используются разные модели.
Модель выбирается автоматически на основе списка языков, указанных в запросе в свойстве "language_codes": ["*"], чтобы сервис выбрал наиболее подходящую модель.
Для каждой запрошенной возможности (feature) используется только одна модель. Например, если на изображении текст на китайском и японском, то распознан будет только один из этих языков. Чтобы распознать языки из разных моделей, укажите несколько возможностей в запросе.
Примеры смотрите в инструкции Распознавание текста.
Совет
Для текста на русском и английском лучше всего работает англо-русская модель. Чтобы использовать ее укажите один из этих языков или оба, но не указывайте другие языки в той же конфигурации.
Поиск текста на изображении
Сервис выделяет найденный текст на изображении и группирует его по уровням: слова группируются в строки, строки в блоки, блоки в страницы.

В результате сервис возвращает JSON-объект, где для каждого из уровней дополнительно указывается:
- страницы (
pages[]) — размер страницы; - блоки текста (
blocks[]) — расположение текста на странице; - строки (
lines[]) — расположение и достоверность распознавания; - слова (
words[]
Чтобы показать расположение текста, сервис возвращает координаты прямоугольника, обрамляющего текст. Координаты — количество пикселей от левого верхнего угла на изображении.
Координаты прямоугольника считаются от левого верхнего угла и указываются против часовой стрелки:
Пример распознанного слова с координатами:
{ "boundingBox": { "vertices": [{ "x": "410", "y": "404" }, { "x": "410", "y": "467" }, { "x": "559", "y": "467" }, { "x": "559", "y": "404" } ] }, "languages": [{ "languageCode": "en", "confidence": 0.9412244558 }], "text": "you", "confidence": 0.9412244558 }
Требования к изображению
Изображение в запросе должно соответствовать следующим требованиям:
Поддерживаемые форматы файлов: JPEG, PNG, PDF.
MIME-тип файла указывается указывается в свойстве
mime_type. По умолчаниюimage.Максимальный размер файла: 1 МБ.
Размер изображения не должен превышать 20 мегапикселей (длина x ширина).
Достоверность распознавания
Достоверность распознавания показывает уверенность сервиса в результате. Например, значение "confidence": 0.9412244558 для строки
означает, что с вероятностью в 94% текст распознан корректно.
Сейчас достоверность считается только для строк. В значение confidence для слов и языка подставляется значение для confidence строки.
Что дальше
cloud.yandex.ru
Распознавание текста с помощью OCR / Habr
Tesseract — это движок оптического распознавания символов (OCR) с открытым исходным кодом, является самой популярной и качественной OCR-библиотекой.
OCR использует нейронные сети для поиска и распознавания текста на изображениях.
Tesseract ищет шаблоны в пикселях, буквах, словах и предложениях, использует двухэтапный подход, называемый адаптивным распознаванием. Требуется один проход по данным для распознавания символов, затем второй проход, чтобы заполнить любые буквы, в которых он не был уверен, буквами, которые, скорее всего, соответствуют данному слову или контексту предложения.
На одном из проектов стояла задача распознать чеки с фотографий.
Инструментом для распознавания был использован Tesseract OCR. Плюсами данной библиотеки можно отметить обученные языковые модели (>192), разные виды распознавания (изображение как слово, блок текста, вертикальный текст), легкая настройка. Так как Tesseract OCR написан на языке C++, был использован сторонний wrapper c github.
Различиями между версиями являются разные обученные модели (версия 4 имеет большую точность, поэтому мы использовали её).
Нам потребуются файлы с данными для распознавания текста, для каждого языка свой файл. Скачать данные можно по ссылке.
Чем лучше качество исходного изображения (имеют значение размер, контрастность, освещение), тем лучше получается результат распознавания.
Также был найден способ обработки изображения для его дальнейшего распознавания путем использования библиотеки OpenCV. Так как OpenCV написан на языке C++, и не существует оптимального для нашего решения написанного wrapper’а, было решено написать собственный wrapper для этой библиотеки с необходимыми для нас функциями обработки изображения. Основной сложностью является подбор значений для фильтра для корректной обработки изображения. Также есть возможность нахождения контуров чеков/текста, но не изучено до конца. Результат получился лучше (на 5-10%).
Параметры:
language — язык текста с картинки, можно выбрать несколько путем их перечисления через «+»;
pageSegmentationMode — тип расположения текста на картинке;
charBlacklist — символы, которые будут игнорироваться ignoring characters.
Использование только Tesseract дало точность ~70% при идеальном изображении, при плохом освещении/качестве картинки точность была ~30%.
Vision + Tesseract OCR
Так как результат был неудовлетворителен, было решено использовать библиотеку от Apple — Vision. Мы использовали Vision для нахождения блоков текста, дальнейшего разделения изображения на отдельные блоки и их распознавания. Результат был лучше на ~5%, но и появлялись ошибки из-за повторяющихся блоков.
Недостатками этого решения были:
- Скорость работы. Скорость работы уменьшилась >4 раза (возможно, существует вариант распоточивания)
- Некоторые блоки текста распознавались более 1 раза
- Текст распознается справа налево, из-за чего текст с правой части чека распознавался раньше, чем текст слева.
MLKit
Еще одним из методов определения текста является MLKit от Google, развернутый на Firebase. Данный метод показал наилучшие результаты (~90%), но главным недостатком этого метода является поддержка только латинских символов и сложная обработка разделенного текста в одной строке (наименование — слева, цена — справа).
В итоге можно сказать, что распознать текст на изображениях — задача выполнимая, но есть некоторые трудности. Основной проблемой является качество (размер, освещенность, контрастность) изображения, которую можно решить путем фильтрации изображения. При распознавании текста при помощи Vision или MLKit были проблемы с неверным порядком распознавания текста, обработкой разделенного текста.
Распознанный текст может быть в ручную откорректирован и пригоден к использованию; в большинстве случаев при распознавании текста с чеков итоговая сумма распознается хорошо и не нуждается в корректировках.
habr.com
Как распознать текст с картинки

В последнее время можно все чаще столкнуться с ситуацией, когда нужно перевести какой-либо текст, содержащийся на изображениях, в электронную текстовую форму. Для того чтобы сэкономить время и не перепечатывать вручную, следует использовать специальные компьютерные приложения для распознавания текста, о чем мы и расскажем сегодня.
Как оцифровать текст
На рынке представлено немало приложений для оцифровки текста, поэтому каждый пользователь найдёт решение, соответствующее требованиям.
Способ 1: ABBYY FineReader
Это условно-бесплатное приложение от российского разработчика обладает огромнейшим функционалом и позволяет не только распознавать текст, но и производить его редактирование, сохранение в различных форматах и сканирование бумажных исходников.
Скачать ABBYY FineReader
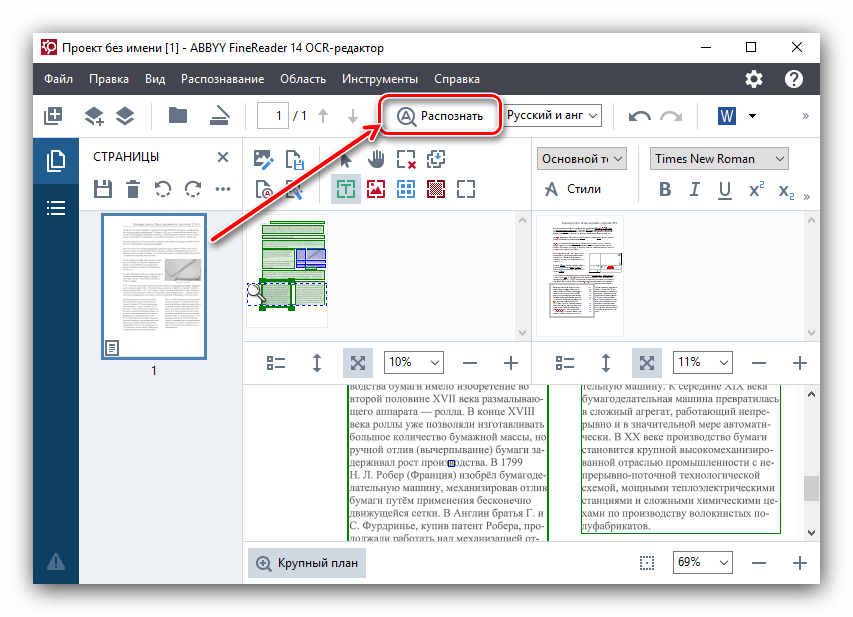
- Чтобы распознать текст на картинке, прежде всего, нужно загрузить её в программу. Для этого после запуска ABBYY FineReader жмем на кнопку «Открыть в OCR редакторе».

После выполнения данного действия открывается окно выбора источника, где вы должны найти и открыть нужное изображение. Поддерживаются следующие популярные форматы: JPEG, PNG, GIF, TIFF, XPS, BMP и др., а также файлы PDF и DjVU.
- После загрузки в ABBYY FineReader автоматически начинается процесс распознавания текста на картинке без вашего вмешательства.
В случае если вы хотите произвести повторную процедуру распознавания, достаточно просто нажать кнопку «Распознать» в верхнем меню. - Иногда не все символы программа может распознать корректно. Это может быть в том случае, если изображение на исходнике не слишком качественное, очень мелкий шрифт, в тексте используется несколько разных языков, применяются нестандартные символы. Но это не беда, так как ошибки можно исправить вручную, с помощью текстового редактора и набора инструментов, которые в нем содержатся.
Для облегчения поиска неточностей оцифровки программа по умолчанию выделяет возможные ошибки бирюзовым цветом.
- Закономерным окончанием процесса распознавания является сохранение его результатов. Для этого жмем кнопку «Сохранить» на верхней панели меню. По умолчанию она имеет вид иконки старого логотипа Microsoft Word. Перед нами появляется окно, где можно самостоятельно определить будущее местонахождение, в котором будет располагаться файл с распознанным текстом, а также его формат. Доступны следующие варианты для сохранения: DOC, DOCX, RTF, PDF, ODT, HTML, TXT, XLS, XLSX, PPTX, CSV, FB2, EPUB, DjVU.





ABBYY FineReader представляет собой самое продвинутое решение, но однозначно рекомендовать именно его мешают платная модель распространения и ограничения пробной версии.
Способ 2: Readiris
Приложение Readiris укрепилось на рынке как ближайший конкурент упомянутого выше Файн Ридер – оно предоставляет подобный функционал, некоторые аспекты исполняет несколько лучше, чем продукция ABBYY.
Скачать Readiris
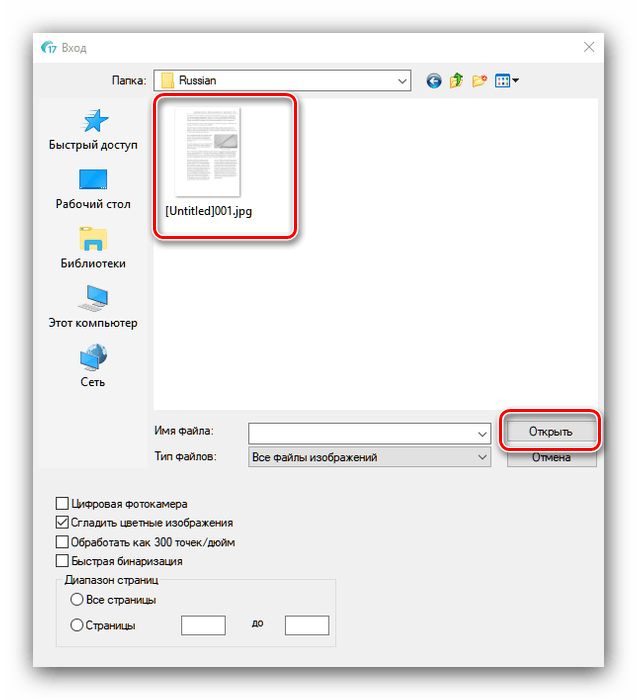
- После запуска приложения выберите источник данных для оцифровки – со сканера или же с готового графического файла.
В примере мы будем использовать последний вариант – для него следует воспользоваться кнопкой «Из файла». - Откроется диалоговое окно «Проводника», в котором следует выбрать нужные документы. Поддерживается большинство графических форматов, а также PDF.
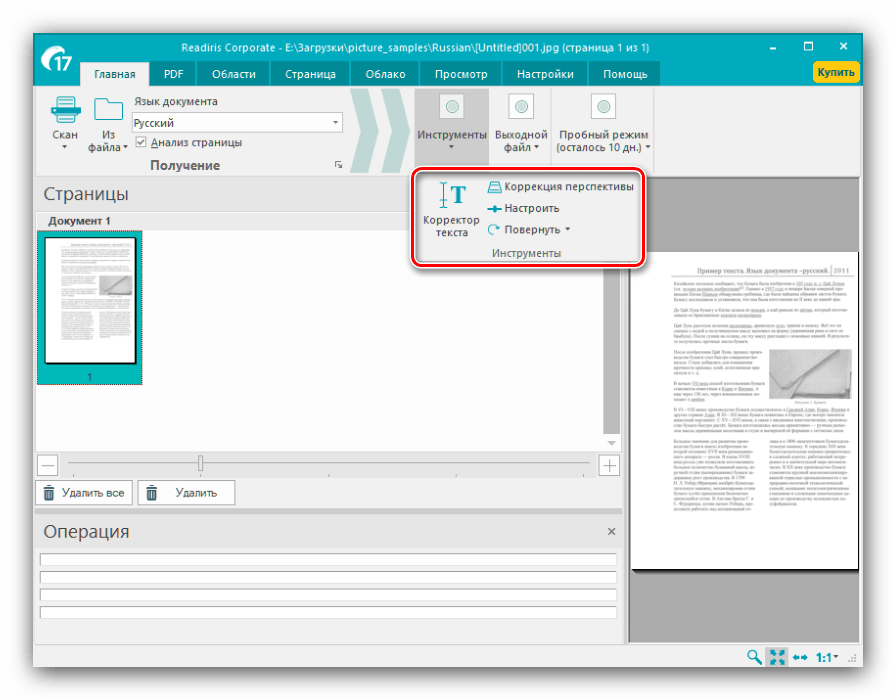
- Подождите, пока документ будет загружен в программу, после чего следует настроить распознавание текста. Первым делом нужно установить основной язык – выберите его из выпадающего меню.
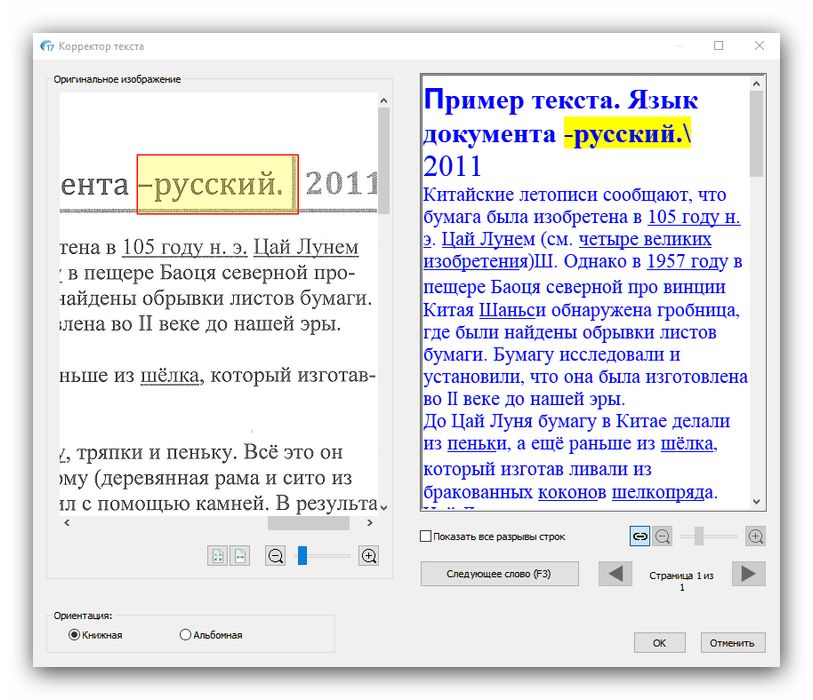
Также рекомендуем отметить опцию «Анализ текста», благодаря которой значительно повыситься качество оцифровки. - Далее обратитесь к меню «Инструменты» — имеющиеся в нём параметры помогут решить некоторые проблемы сканирования, такие как искажение перспективы, недостаточная контрастность картинки или смещение текста относительно полотна.
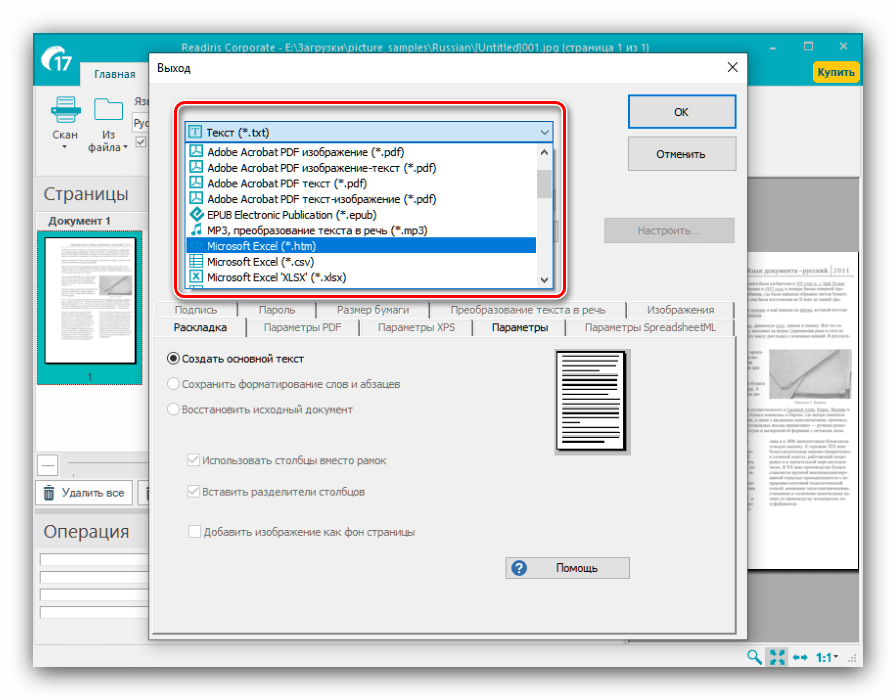
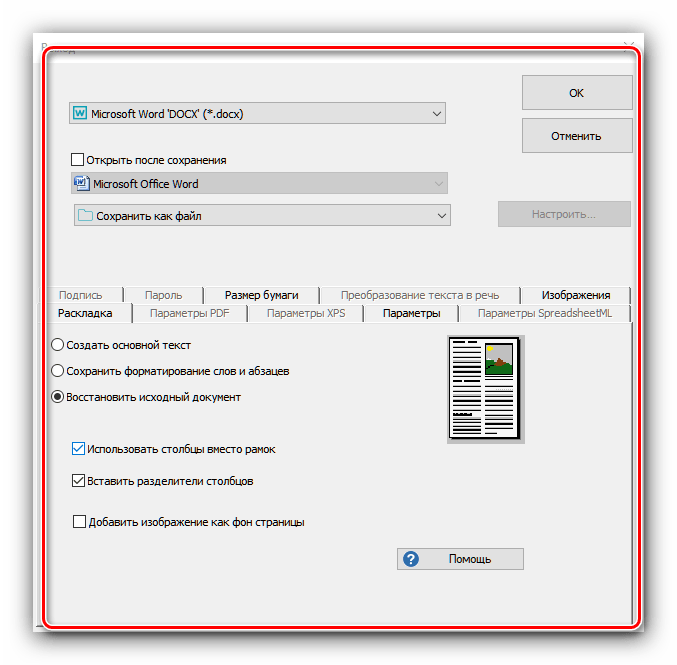
Из этого меню также можно подкорректировать текст, если распознавание сработало неправильно. - После внесения изменений в распознанный текст следует задать выходной формат полученных данных через одноименное меню в панели инструментов. Основными форматами считаются PDF, а также файлы Microsoft Office (DOCX и XLSX) – кликните по требуемой позиции для выбора.
Все возможные форматы экспорта сгруппированы в пункте «Другое». Кроме упомянутых выше типов файлов, оцифрованный текст можно сохранить в виде данных OpenOffice, гипертекстовых файлов или обычных TXT. - После выбора формата откроется окошко Мастера по экспорту. В нём можно настроить те или иные параметры полученного файла (зависят от выбранного формата) и вариант сохранения (локальный или в облачный сервис). После внесения всех требуемых изменений нажмите «ОК».
Снова появится окно «Проводника», в котором следует выбрать желаемый конечный каталог сохранения.





В целом Readiris представляет собой удобное и современное решение для оцифровки текста, однако весомым его недостатком можно назвать платную модель распространения.
Способ 3: RiDoc
Ещё одно приложение, ориентированное на работу со сканерами, однако умеющее работать и с локальными файлами в разных форматах.
Скачать RiDoc
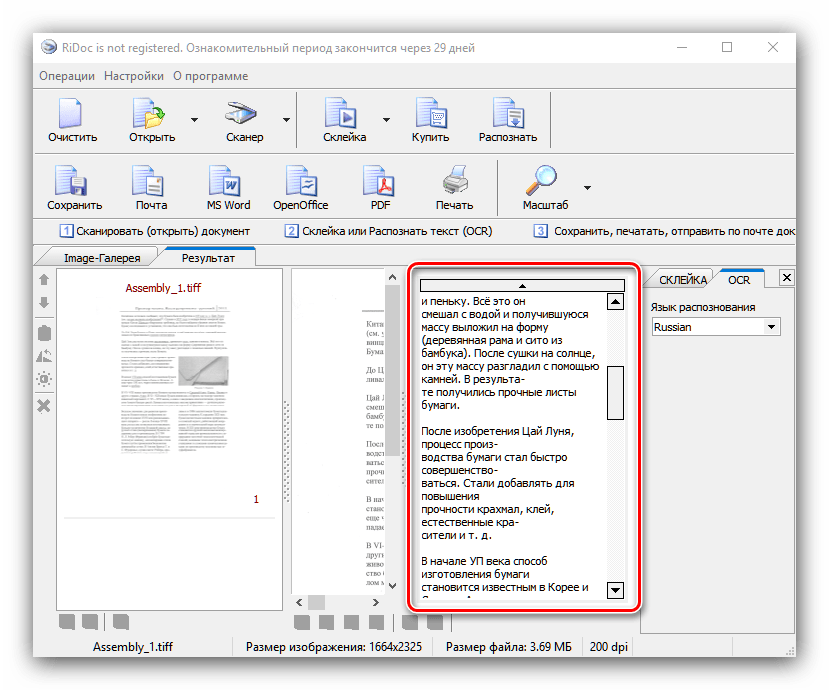
- Откройте приложение. Для начала работы используйте на панели инструментов кнопки «Открыть» или «Сканер» – первая отвечает за распознавание текста в локальных файлах, вторая позволяет начать оцифровку одновременно со сканированием. Для примера будем использовать первый вариант.
- В окне «Проводника» перейдите к документу, из которого требуется получить текст, и выберите его. Доступна также пакетная обработка документов.
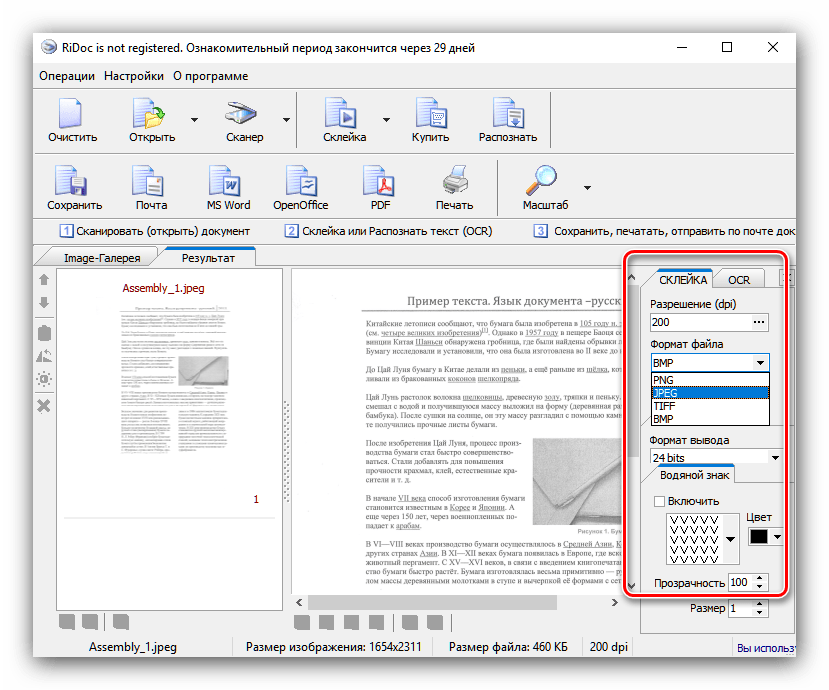
- Если требуется, можно обработать полученный файл: обрезать картинку, установить область распознавания, исправить огрехи сканирования.
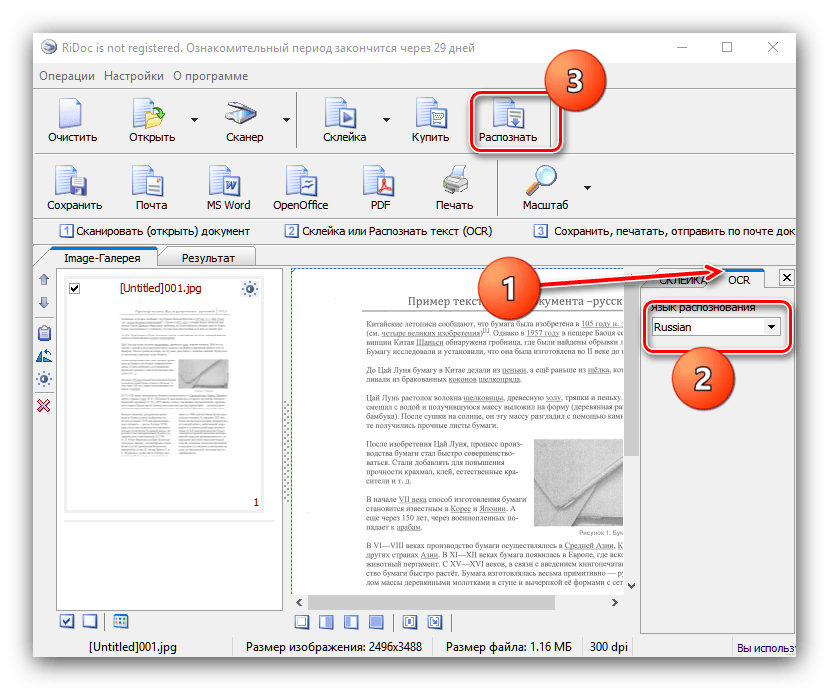
Отдельным пунктом стоит возможность склейки – в этом случае мультистраничный документ будет сохранён единым файлом. Можно выбрать значение DPI и формат вывода (доступны только файлы изображений). - Для распознавания текста в правой части окна найдите вкладку «OCR» и откройте её. Доступных опций не много – можно выбрать только язык документа. После смены пакета нажмите на кнопку «Распознать» на панели инструментов.
Отсюда же можно подправить результаты оцифровки. - Сохранение документов доступно в двух вариантах – прямое или экспорт в офисные приложения. Для выполнения первого способа следует использовать кнопку «Сохранить». Откроется окно, в котором можно выбрать место сохранения, а также тип (единичные файлы или один многостраничный). Формат сохраняемого файла зависит от выбранного на этапе склейки.
Экспорт результатов возможен в текстовые процессоры офисных пакетов Microsoft или OpenOffice, в виде электронного письма (кнопка «Почта»), в формат PDF или же печати на принтере. Для экспорта в офисные программы они должны быть установлены на компьютере, тогда как сохранение в ПДФ возможно даже без соответствующих приложений.




Как видим, РиДок представляет собой небогатое возможностями решение, но для несложных вариантов оцифровки вполне подойдёт.
Способ 4: Capture2Text
Небольшая утилита, которая позволяет распознавать текст из любой области на экране компьютера, полностью бесплатная и удобная в использовании.
Скачать Capture2Text с официального сайта
- Загрузите архив с программой и распакуйте его в любое удобное место. Затем перейдите к полученному каталогу и запустите исполняемый файл.
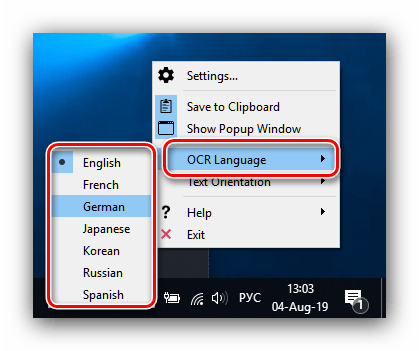
Далее откройте системный трей – в нём должна появится иконка утилиты.
Для изменения языка распознавания кликните правой кнопкой мыши по значку Capture2Text в системном трее, затем в настройках выберите пункт «OCR Language» и установите нужный язык.
- Откройте файл, текст с которого требуется оцифровать, например, документ DjVU без текстового слоя. Когда файл будет открыт, нажмите сочетание клавиш Win+Q и выделите область распознавания.
- Появится окошко утилиты с результатами распознавания. Полученные данные можно скопировать в любое приложение, поддерживающее ввод пользовательского текста.




Приложение невероятно простое, но это оборачивается ограниченным функционалом и, порой, некорректным распознаванием русского текста. Также к недостаткам можем отнести отсутствие локализации на русский язык. Впрочем, для некоторых пользователей эти минусы несущественны, а основных возможностей будет вполне достаточно.
Способ 5: CuneiForm
Ещё одно решение для оцифровки текста, созданное на постсоветском пространстве. Несмотря на прекращение разработки, по-прежнему актуально.
Скачать CuneiForm
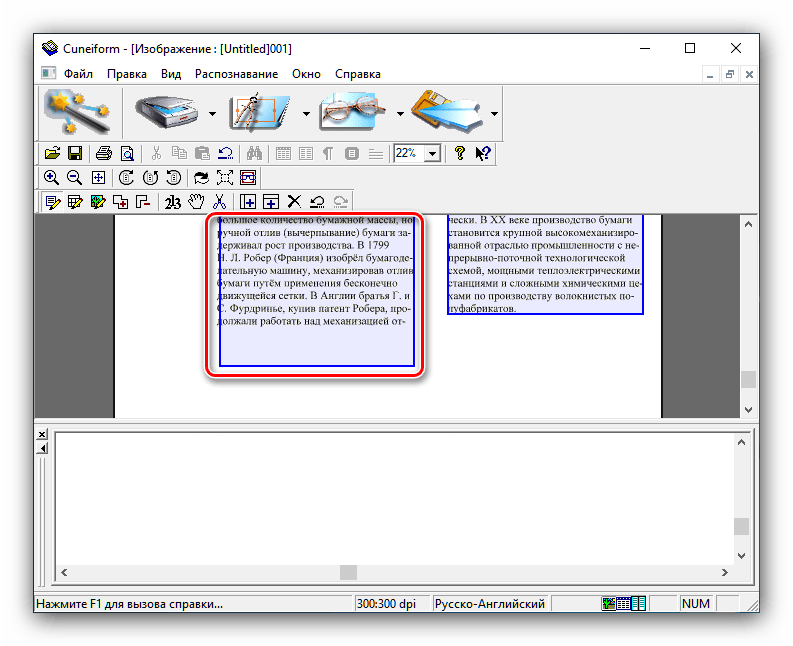
- Как и многие другие представленные в этой статье программы, КунейФорм умеет работать как с готовыми изображениями, так и получать данные напрямую со сканера. Воспользуемся первым вариантом – для этого откройте меню «Файл» и выберите в нём пункт «Открыть».
- Посредством «Проводника» выберите требуемый файл или файлы.
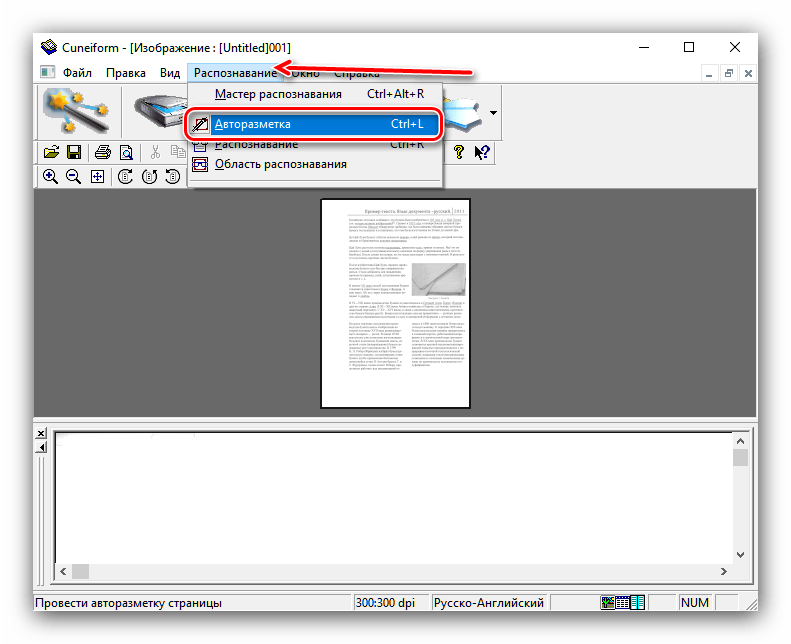
- После загрузки данных в программу используйте пункты «Распознавание» – «Авторазметка».
Это позволит выбрать области с текстом для более корректной работы модуля OCR. Если автоматические алгоритмы неправильно разметили страницу, области с текстом можно подправить вручную или вообще убрать. - Далее можно заниматься непосредственно оцифровкой. Снова откройте меню «Распознавание» и выберите вариант с таким же наименованием.
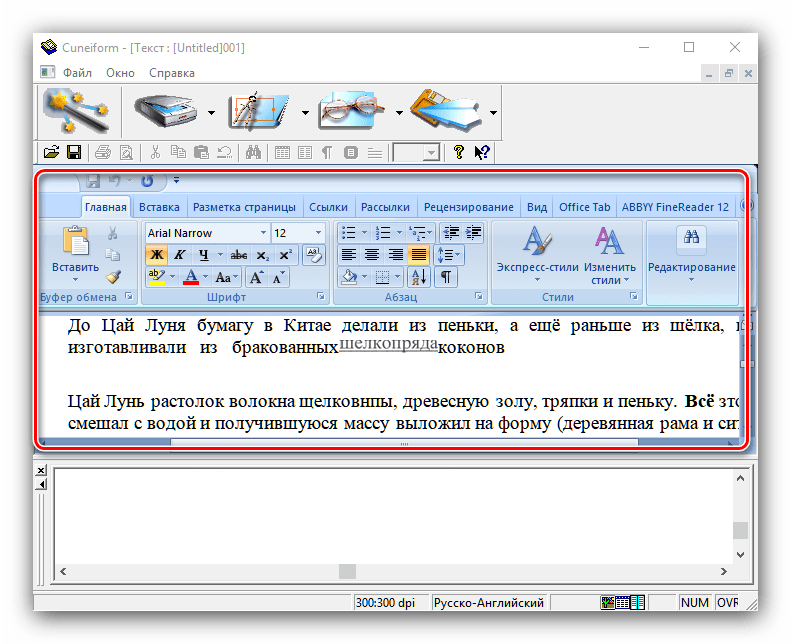
- Распознанный текст будет открыт в окне приложения, где его также можно редактировать. Возможности довольно обширные, и соответствуют полноценному текстовому редактору. В случае если на компьютере установлен MS Word, полученные данные будут открыты через его интерфейс.
- Сохранение результатов работы доступно по пунктам «Файл» – «Сохранить».
В открывшемся «Проводнике» выберите местоположение полученного файла и его формат. Поддерживаются не много вариантов: TXT, RTF, внутренний формат FED, а также экспорт в приложения Microsoft Office (Word и Excel).




Как видим, CuneiForm представляет собой простой и в то же время мощный инструмент для оцифровки текста. Весомым его преимуществом будет свободная модель распространения, однако недостатки в виде окончания поддержки и отсутствия формата PDF могут заставить обратиться к альтернативам.
Заключение
Как видим, распознать текст с картинки довольно просто, если использовать для этого специализированные приложения. Данная процедура не потребует от вас много усилий, а польза будет в огромной экономии времени.
 Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.Помогла ли вам эта статья?
ДА НЕТlumpics.ru
Распознавание текста онлайн бесплатно с картинки
При работе с изображениями и pdf-файлами может возникнуть необходимость распознать имеющуюся на них надпись. В реализации данной задачи эффективную помощь окажут специальные сетевые сервисы. В данном материале я разберу, каким образом можно выполнить распознавание текста в режиме онлайн абсолютно бесплатно с любой картинки. А также какие сетевые сервисы нам в этом помогут.
Особенности работы сервисов для распознавания текста с картинки
В сети присутствует достаточное количество сервисов, позволяющих прочитать надпись с изображения online. Обычно в их названии (или описании) упоминается аббревиатура «OCR» (Optical Recognition Technology – Технология оптического распознавания).
В большинстве своём такие сервисы имеют условно-бесплатный характер, по которому бесплатное идентифицирование текста доступно объёмом до 10 страниц (изображений). Если же пользователь желает распознать текст большего объёма, сервис потребует приобрести платный функционал.
Качество распознавания русскоязычного текста зависит от качества источника, и варьируется от хорошего к среднему. Высоким уровнем распознавания могут похвастаться лишь несколько источников (к примеру, Гугл Диск), другие альтернативы распознают текст довольно посредственно.
Принцип работы с такими ресурсами довольно прост:
- Вы выполняете переход на такой сайт, загружаете на него картинку (или нужный pdf-файл).
- Выбираете язык обработки.
- Жмёте на кнопку активации распознавания.
- Через некоторое время, зависящее от объёма файла и скорости работы ресурса, вы получите возможность скачать полученный результат на ПК.
Полученный текст рекомендуется вычитать, дабы избавиться от допущенных сервисами огрехов. Давайте рассмотрим список инструментов, позволяющих определить содержание текста с любой картинки в режиме онлайн.
Читайте также: Голосовой ввод текста онлайн — ТОП-4 способа.
Функционал популярного облачного хранилища «Гугл.Диск» позволяет выполнять качественное распознавание как с картинок (JPEG, PNG, GIF), так и с pdf-файлов. Поддерживаются файлы до 2 мегабайт, имеется автораспознавание языка текста в документе, при этом хорошо распознаётся текст, высота букв которого составляет не менее 10 пикселей.
Для выполнения распознавания:
- Перейдите на drive.google.com и нажмите на «Создать» — «Загрузить файлы».
- Файл появится в перечне загруженных файлов.
- Наведите на него курсор, щёлкните правой клавишей мышки, выберите «Открыть с помощью», а затем «Google Документы».
Откройте ваш файл с помощью Гугл Документы
- Файл будет распознан и откроется. В открывшемся документе сверху будет находиться само изображение, а под ним будет располагаться распознанный текст.
- Для сохранения результата нажмите на «Файл» — «Скачать как» и выберите нужный вам формат.
Скачайте полученный результат


Сервис newocr.com – один из самых популярных в англоязычном сегменте инструментов для распознавания текста. Он имеет полностью бесплатный характер, поддерживает нелимитированное количество файлов для распознавания, не требует регистрации, работает с 106 языками. Распознаются форматы JPEG, PNG, GIF, PDF, DjVu, ZIP-архивы и другие. Пользователь может выбрать, какую часть изображения необходимо распознать.
Порядок действий:
- Запустите newocr.com, нажмите на «Обзор» и загрузите ваш файл.
- В поле «Recognition language» добавьте языки для распознавания (по умолчанию это Russian и English).
- Нажмите на «Upload» и дождитесь окончания процесса распознавания.
- Затем откроется окно с распознанным текстом, вы сможете как скачать его в формате «txt», так и скопировать в Word через Ctrl+C и Ctrl+V.
Внешний вид сервиса newocr.com

Это может быть полезным: Проверить запятые в тексте онлайн.
Функционал русскоязычного сервиса img2txt.com предназначен для быстрого распознавания текста из различных изображений. Поддерживаются множество языков, графически форматы jpg, png, bmp (формат pdf не поддерживается). Максимальный размер загружаемого изображения не должен быть более четырёх мегабайт.
Работа с сервисом не отличается от других аналогов:
- Вы выполняете вход на img2txt.com, нажимаете на «Обзор» — «Загрузить» для загрузки изображения.
- Затем выбираете язык, на котором написан распознаваемый текст.
- Нажимаете на «Начать распознавание».
- Через несколько секунд получаете результат.
Распознавание текста на img2txt.com

Сайт finereaderonline.com является продуктом российской компании «ABBYY», известной своими программными решениями в области OCR, лингвистики и перевода. Предлагаемый компанией онлайн инструментарий позволяет выполнять бесплатное распознавание изображений (в том числе pdf) размером до 10 страниц на более чем 190 языках.
Работа с ресурсом не отличается от аналогов:
- Переходите на finereaderonline.com и жмёте на «Начать».
- Затем кликните на «Загрузить файлы», выберите необходимый язык документа, и формат сохранения конечного файла.
- Затем жмите на «Распознать».
Convertio.co – бесплатная конвертация текста
Данный сайт представляет собой довольно универсальный конвертер, умеющий преобразовывать файлы из одного формата в другой. В его функционал также включён инструментарий для бесплатного распознавания текста онлайн в редактируемые форматы Word, Excel и txt.
При этом для распознавания больше десяти изображений будет необходимо пройти регистрацию на ресурсе:
- Запустите convertio.co, кликните на «С компьютера» для загрузки файла, или выберите одно из облачных хранилищ для загрузки файла с облака.
- Выберите язык распознавания, конечный формат документа (к примеру, docx).
- Введите капчу, затем нажмите на «Преобразовать».

Функционал сервиса convertio.co
Onlineocr.net – быстрое распознавание текста из pdf онлайн
Англоязычный сервис onlineocr.net по своему функционалу не отличается от других ресурсов данного типа. При этом качество его распознавания находится на довольно среднем уровне, поддерживается лишь несколько конечных форматов, без регистрации на ресурсе возможно распознавание пятнадцати изображений в час.
Работа с ресурсом шаблонна, и не отличается от других сервисов данного плана.

Конвертер onlineocr.net
Рекомендуем к прочтению: Поиск песни по словам из текста.
Заключение
Выше мной были перечислены ресурсы, позволяющие выполнить распознавание текста бесплатно с любой картинки в режиме онлайн. При работе с оными рекомендуется вычитать и отредактировать полученный с их помощью текст, так как в некоторых случаях качество распознавания может желать лучшего. Если полученный итог вас категорически не устроил, стоит обратиться к функционалу стационарных программ («ABBYY FineReader», «OCR CuneiForm», «SimpleOCR» и других) для получения удовлетворяющего вас результата.
sdelaicomp.ru
новые возможности фреймворка Vision / Dodo Pizza Engineering corporate blog / Habr
Теперь фреймворк Vision умеет распознавать текст по-настоящему, а не как раньше. С нетерпением ждём, когда сможем применить это в Dodo IS. А пока перевод статьи о распознавании карточек из настольной игры Magic The Gathering и извлечении из них текстовой информации.Впервые фреймворк Vision был представлен широкой общественности на WWDC в 2017 году, вместе с iOS 11.
Vision был создан, чтобы помочь разработчикам классифицировать и идентифицировать объекты, горизонтальные плоскости, штрих-коды, выражения лица и текст.
Однако с распознаванием текста была проблема: Vision мог найти место, где находится текст, но фактического распознавания текста не происходило. Конечно, было приятно видеть ограничивающую рамку вокруг отдельных фрагментов текста, но затем их нужно было вытаскивать и распознавать самостоятельно.
Эту проблему решили в обновлении Vision, которое вошло в iOS 13. Теперь Vision framework предоставляет истинное распознавание текста.
Чтобы проверить это, я создал очень простое приложение, которое может распознать карточку из настольной игры Magic The Gathering и извлекать из нее текстовую информацию:
- имя карты;
- код выпуска;
- коллекционный номер (он же индекс).
Вот пример карты и выделенного текста, который я хотел бы получить.
Глядя на карточку вы можете подумать: «Этот текст довольно мелкий, плюс на карточке есть много другого текста, который может помешать». Но для Vision это не проблема.
Для начала нам нужно создать VNRecognizeTextRequest. По сути, это описание того, что мы надеемся распознать, плюс настройка языка распознавания и уровень точности:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText)
request.recognitionLevel = .accurate
request.recognitionLanguages = ["en_GB"]Блок завершения имеет вид
handleDetectedText(request: VNRequest?, error: Error?). Мы передаём его в конструктор VNRecognizeTextRequest и затем устанавливаем оставшиеся свойства.Доступно два уровня точности распознавания: .fast и .accurate. Поскольку на нашей карточке довольно маленький текст в нижней части, я выбрал более высокую точность. Быстрый же вариант скорее лучше подойдет для больших объемов текста.
Я ограничил распознавание британским английским, так как все мои карты именно на нём.Вы можете указать несколько языков, но при этом нужно понимать, что сканирование и распознавание может занять немного больше времени для каждого дополнительного языка.
Есть еще два свойства, которые стоит упомянуть:
customWords: вы можете добавить массив строк, которые будут использоваться поверх встроенного лексикона. Это полезно, если в вашем тексте есть какие-нибудь необычные слова. Я не применял опцию для этого проекта. Но если бы я делал коммерческое приложение-распознавалку для карточек Magic The Gathering, то добавил бы некоторые из наиболее сложных карт (например, Fblthp, the Lost), чтобы избежать проблем.minimumTextHeight: это float-значение. Оно обозначает размер относительно высоты изображения, при котором текст больше не должен быть распознан. Если бы я создавал этот сканер, чтобы просто получить имя карты, это было бы полезно для удаления всего другого текста, который не нужен. Но мне нужны самые маленькие кусочки текста, поэтому пока я проигнорировал это свойство. Очевидно, при игнорировании мелких текстов скорость распознавания будет выше.
Теперь, когда у нас есть наш запрос, его вместе с картинкой надо передать обработчику запросов:
let requests = [textDetectionRequest]
let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:])
DispatchQueue.global(qos: .userInitiated).async {
do {
try imageRequestHandler.perform(requests)
} catch let error {
print("Error: \(error)")
}
}Я использую изображение прямо с камеры, преобразовав его из
UIImage в CGImage. Это используется в VNImageRequestHandler вместе с флагом ориентации, чтобы помочь обработчику понять, какой текст он должен распознавать.В рамках этого демо я использую телефон только в портретной ориентации. Поэтому, естественно, я добавляю ориентацию .right. Так, падажжи!
Оказывается, ориентация камеры на вашем устройстве полностью отделена от вращения устройства и всегда считается слева (как по умолчанию было принято в 2009 году, что для съемки фотографий нужно держать телефон в альбомной ориентации). Конечно, времена изменились, и мы в основном снимаем фотографии и видео в формате портретной ориентации, но камера по-прежнему выровнена слева.
Как только наш обработчик настроен, мы переходим в поток с приоритетом .userInitiated и пытаемся выполнить наши запросы. Вы можете заметить, что это массив запросов. Так происходит, потому что вы можете попытаться вытащить несколько фрагментов данных за один проход (т. е. идентифицировать лица и текст из одного и того же изображения). Если ошибок нет, обратный вызов, созданный с помощью нашего запроса, будет вызван после обнаружения текста:
func handleDetectedText(request: VNRequest?, error: Error?) {
if let error = error {
print("ERROR: \(error)")
return
}
guard let results = request?.results, results.count > 0 else {
print("No text found")
return
}
for result in results {
if let observation = result as? VNRecognizedTextObservation {
for text in observation.topCandidates(1) {
print(text.string)
print(text.confidence)
print(observation.boundingBox)
print("\n")
}
}
}
}Наш обработчик возвращает наш запрос, который теперь имеет свойство results. Каждый результат является
VNRecognizedTextObservation, у которого для нас есть сразу несколько вариантов результата (далее — кандидаты).Вы можете получить до 10 кандидатов на каждую единицу распознанного текста, и они сортируются в порядке убывания уверенности. Это может быть полезным, если у вас есть определенная терминология, которую синтаксический анализатор неправильно распознает с первой попытки. Но определяет правильно позже, даже если он менее уверен в правильности результата.
В этом примере нам нужен только первый результат, поэтому мы проходимся циклом по observation.topCandidates(1) и извлекаем как текст, так и уверенность. В то время как сам кандидат имеет различный текст и уверенность, .boundingBox остается той же. .boundingBox использует нормализованную систему координат с началом координат в левом нижнем углу, поэтому, если она в дальшнейем будет использоваться в UIKit, для вашего же удобства её надо преобразовать.
Это почти всё, что нужно. Если я прогоню фотографию карты через это, я получу следующий результат чуть менее чем за 0,5 секунд на iPhone XS Max:
Carnage Tyrant
1.0
(0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786)
Creature
1.0
(0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635)
Dinosaur
1.0
(0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364)
Carnage Tyrant can't be countered.
1.0
(0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906)
Trample, hexproof
0.5
(0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653)
Sun Empire commanders are well versed
1.0
(0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302)
in advanced martial strategy. Still, the
1.0
(0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136)
correct maneuver is usually to deploy the
1.0
(0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009)
giant, implacable death lizard.
1.0
(0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258)
7/6
0.5
(0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593)
179/279 M
1.0
(0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193)
XLN: EN N YEONG-HAO HAN
0.5
(0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319)
TN & 0 2017 Wizards of the Coast
1.0
(0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)Это невероятно! Каждый фрагмент текста был распознан, помещен в его собственную ограничивающую рамку и возвращен в результате с рейтингом доверия 1.0.
Даже очень маленький копирайт в основном корректен. Все это было сделано на изображении 3024×4032 весом в 3,1 МБ. Процесс был бы еще быстрее, если бы я сначала уменьшил изображение. Также стоит отметить, что этот процесс намного быстрее на новых бионических чипах A12, которые имеют специальный нейронный движок.
Когда текст распознан, последнее, что нужно сделать, это вытащить нужную мне информацию. Я не буду помещать весь код здесь, но ключевая логика состоит в том, чтобы перебирая каждую .boundingBox определять местоположение, чтобы я мог выбрать текст в нижнем левом углу и в верхнем левом углу, игнорируя что-либо дальше справа.
Конечным результатом получилось приложение сканирующее карточку и возвращающее мне результат менее, чем за одну секунду.
P.S. На самом деле мне нужен только код выпуска и коллекционный номер (он же индекс). Затем их можно использованы в API сервиса Scryfall для получения всей возможной информации об этой карте, включая правила игры и стоимость.
Пример приложения доступен на GitHub.
habr.com
Что вы видите на этой картинке? — Блог Яндекса
25 марта 2015, 13:11
Распознавание изображений — одна из самых сложных задач для компьютера. Мы уже рассказывали о том, как устроено компьютерное зрение и как оно применяется в наших сервисах — например, при поиске похожих изображений в Яндекс.Картинках. Теперь технология компьютерного зрения работает и в Яндекс.Диске — благодаря ей вы можете найти изображения форматов JPEG, GIF и PNG, содержащие текст поискового запроса. Достаточно ввести в поисковую строку нужное слово, и система найдёт на Диске картинки, на которых оно встретится. В результатах поиска вы увидите изображения с этим словом, документы, в тексте которых оно содержится, а также файлы и папки, в названиях и описаниях которых есть это слово.Когда на Диске тысячи фотографий, разложенных по разным папкам, поиск по текстам позволит быстро найти среди них нужную. Например, скан договора с названием вроде scan723.JPG или фотографию визитки человека, с которым понадобилось связаться. Искать можно не только документы, но и любые фотографии, которые сделаны для того, чтобы сохранить текст, будь то объявление на двери подъезда или любопытный рекламный плакат в метро.
В основе поиска текстов на изображениях лежит технология оптического распознавания символов. Систем распознавания, опирающихся на эту технологию, много, и все они разные. Какие-то решают определённую задачу, например распознают партитуры, какие-то работают только с чистым текстом. Для Яндекс.Диска мы разработали свою универсальную систему, способную распознавать текст на картинках разных по виду, содержанию и, главное, качеству.
Система состоит из двух частей — классификатора картинок и модуля распознавания. Сначала классификатор, глубокая нейронная сеть, отбирает из всех картинок те, на которых изображён текст. Он учится отличать их от прочих на огромной базе изображений. Использование машинного обучения позволяет добиться высокого качества распознавания — ведь алгоритм опирается не на какие-то вручную заданные правила, а на опыт анализа миллионов разных картинок. Когда изображения с текстом отобраны, алгоритм находит на них линии, предположительно содержащие текст, — различать их помогает ещё одна нейронная сеть. На следующем этапе алгоритм оставляет только те линии текста, в которых он уверен.
Затем модуль распознавания разбивает линии текста на отдельные символы. Для каждого символа алгоритм выбирает несколько наиболее вероятных вариантов распознавания среди известных ему. Например, это могут быть буквы «О», «о» и цифра «0», очень похожие друг на друга. После этого в дело вступает языковая модель — алгоритм принимает решение, какой из символов-кандидатов подходит лучше всего. Языковая модель опирается на словари и учитывает не только сходство символов с теми, что знает система, но и контекст, то есть соседние символы. Если из нескольких вероятных символов складывается и
yandex.ru